最近看了一部电影《火星救援》,里面有一个情节,男主角通过火星探测器上一个可以旋转的摄像头与地球建立联系。

虽然摄像头可以传输视频信号,但是这个视频传输是单向的,只能从火星传输到地球。地球可以收到火星上的视频信号,但是火星上看不到地球上的视频信号,也就无法完成交流。(当然,建立联系后在工程师的帮助下,直接接入火星探测器电脑系统通讯了就不用这么麻烦了)
地球上可以看到主角写在纸上的字,但是该用什么来接收来自地球的信息呢?好像只有摄像头可以转动这点可以利用了。那么要如何通过这个可以转动的摄像头与地球联系?就像两个聋子,沟通只能靠手语,结合实际情况我们该如何设计这个手语。
其实最直观的就是做26个英文字母的牌子,摆成一圈,摄像镜头转到哪个牌子就表示相应的字母,记录下来不就可以获取信息了吗?似乎可行,但是细想一下,表达信息26个字母好像不够,还有像数字、符号之类的,一起加起来似乎也不少了,这么多牌子摄像头转的过来吗?是不是有点密集,而且只对英语一种语言有效。一种语言有多少字就要多少个牌子??当然这是后话。
能否少用一些牌子,我们需要优化一下这个方法。目前我们也只需要考虑英文这一种语言。
现实是有相应的标准来供我们使用的,那就是ASCII(美国信息交换标准代码),不用我们来发明什么,大家都使用这个规范。影片中也有交代。
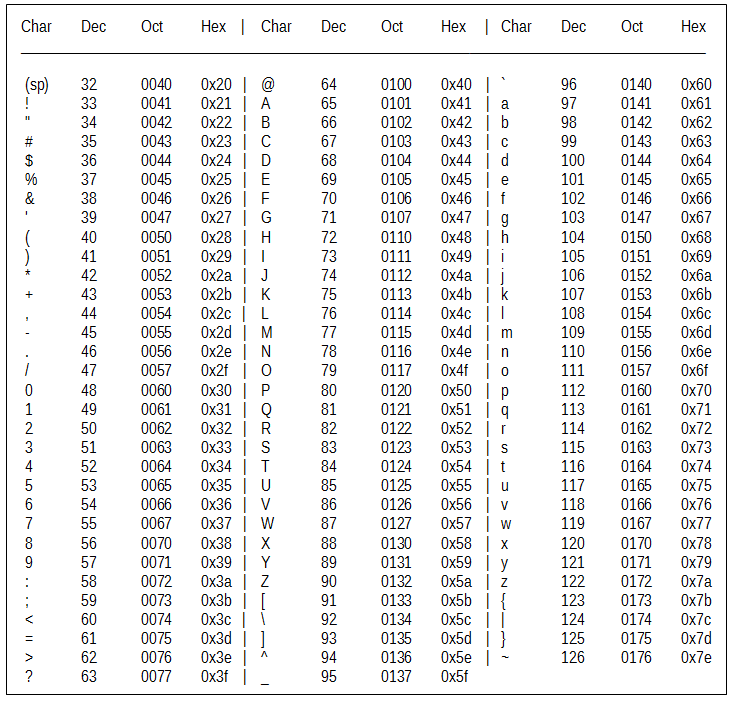 ASCII其实就是一个规定字符及其相应数值的表,字符与其相应的数值一一对应,我们只需要接收数值然后转换回字符就能得到信息了。
ASCII其实就是一个规定字符及其相应数值的表,字符与其相应的数值一一对应,我们只需要接收数值然后转换回字符就能得到信息了。
说到传输数字,有的人会问,不是嫌牌子多么?干嘛不用10进制而要用16进制呢?而且2进制所需要的牌子更少呢!?
我们暂且不谈牌子多少的事情。首先我们知道ASCII定义了128个字符。
如果我们使用十进制数字,那么相对应的我们就要使用0~127这些十进制数。我们来看一下,当我们收到 ‘102103’这串数值的时候,我们遇到了一个问题该如何分开这串数字?
到底是 10 21 03 还是 102 103 呢?
显然我们需要三位数才能包括ASCII的128个字符,那么我们发送数值7的时候我们需要发送007,我们发送数值41的时候我们需要发送041。前面多出来的0也需要发送,所以每发送一个字符就需要3个数字。
如果我们使用16进制呢?最大的两位16进制数是0xFF=255,远大于128,也就是说发送一个字符只需要2个16进制数字就好了。
比如:我们发送数值7的时候我们需要发送十六进制数字07,我们发送数值41的时候我们需要发送十六进制数字29。
那么我们使用2进制呢?0b1111111=127,那么我们发送一个字符需要7个二进制数字。
比如:我们发送数值2的时候我们需要发送二进制数字0000010。(前面的0必须得填满,要不字符之间如何区分?)
那么发送一个字符所需要最少位数字的就是使用16进制了。
在电影中的问题不是发送而是接收,你需要跟着摄像头记录下摄像头指向的数字,接收一个字符用二进制需要摄像头需要转动7下,10进制需要3下,16进制只需要2下。你可能会说,虽然使用二进制数需要更多的转动,但是摄像头转动的角度和距离都更小说不定还更节省时间呢!?可是二进制并不适合人类阅读,电影中都主角是个植物学家恐怕对二进制转换不熟悉,而且ASCII表转换表上估计也没有二进制数而是十六进制数。
各种情况综合考虑,16进制就是比较好的选择。
如果我们需要传输中文怎么办?
借此机会我们就可以来理解 unicode 以及 UTF-8 、GBK,字符集与字符编码的关系了。
其实原理和上面讲的一样。不过是把上面的ASCII表换成unicode表,unicode是一个比ASCII大得多的表。
unicode就是一种字符集,和上面的ASCII一样。而 UTF-8 、GBK 则是字符编码方式,就是上面说的将字符原值转换成其他进制数值来传输,不过转换的规则更复杂一些。
如果不使用字符编码,直接传输字符集中的原值的话,会浪费许多传输、存储空间。映射到影片中的情节就是我们没有这么多牌子,就算有这么多牌子你还找得到你要找的牌子么?
UTF-8 是 Unicode 编码的实现方式之一。UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则可以概括为二条:
1)对于单字节的符号,字节的第一位设为
0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。2)对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。下表总结了编码规则,字母
x表示可用编码的位。Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) --------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是
0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
比如我们收到了这样的一串十六进制数”e4bda0e5a5bdefbc81”(提前约定好是utf-8编码的unicode字符串信息)
解码过程如下:
hex e4 bd a0 e5 a5 bd ef bc 81
bin 11100100 10111101 10100000 11100101 10100101 10111101 11101111 10111100 10000001
decode 0100 111101 100000 0101 100101 111101 1111 111100 000001
bin 01001111 01100000 01011001 01111101 11111111 00000001
hex 4f 60 59 7d ff 01
得到了unicode的十六进制数值,查表可知是4f60是你字,597d是好字,ff01是中文感叹号。
所以发送的是你好!
推荐阅读:
Why does Mark use Hexadecimal to communicate?