
又来参赛了,赛后复盘也很重要! 官方WriteUP
Hackergame 启动
签到题,观察可知自行提交相应的数据就能过关。
这道题最终的完成人数为2025,与上届比赛完成签到题人数2643相比较,下降了好几百人呢。但还是比PKU GeekGame的人数多出了一倍。
猫咪小测
- 想要借阅世界图书出版公司出版的《A Classical Introduction To Modern Number Theory 2nd ed.》,应当前往中国科学技术大学西区图书馆的哪一层?(30 分)提示:是一个非负整数。
12
根据西区图书馆简介可知。
- 今年 arXiv 网站的天体物理版块上有人发表了一篇关于「可观测宇宙中的鸡的密度上限」的论文,请问论文中作者计算出的鸡密度函数的上限为 10 的多少次方每立方秒差距?(30 分)提示:是一个非负整数。
23
- 为了支持 TCP BBR 拥塞控制算法,在编译 Linux 内核时应该配置好哪一条内核选项?(20 分)
提示:输入格式为 CONFIG_XXXXX,如 CONFIG_SCHED_SMT。
CONFIG_TCP_CONG_BBR
直接问的Claude.ai
- 🥒🥒🥒:「我……从没觉得写类型标注有意思过」。在一篇论文中,作者给出了能够让 Python 的类型检查器 MyPY mypy 陷入死循环的代码,并证明 Python 的类型检查和停机问题一样困难。请问这篇论文发表在今年的哪个学术会议上?(20 分)
提示:会议的大写英文简称,比如 ISCA、CCS、ICML。
ECOOP
解这问遇到了点波折,走了点弯路。想尽了各种关键词去搜索,其实在之前就在搜索结果中看到了《Python Type Hints Are Turing Complete》这篇论文,但是在看见这个论文是在2022年9月就发表的情况下,就略了(肯定不会去看论文具体内容啦)。还尝试通过获取相关的中国计算机学会推荐国际学术会议和期刊目录来脚本遍历,谁知道写的脚本在验证返回结果的过程中搞错了条件,其实答案已经在其中了😥。
好在再次检查关键词”mypy Halting Problem”的搜索条目发现了一个2023年的版本得知了ECOOP。
更深更暗
阅读源码main.js可知flag生成方式
let token = "[your token]";
let hash = CryptoJS.SHA256(`dEEper_@nd_d@rKer_${token}`).toString();
console.log(`flag{T1t@n_${hash.slice(0, 32)}}`);
旅行照片 3.0
题目 1-2
1、你还记得与学长见面这天是哪一天吗?(格式:yyyy-mm-dd) 2023-08-10
2、在学校该展厅展示的所有同种金色奖牌的得主中,出生最晚者获奖时所在的研究所缩写是什么? HFNL
先根据第一张诺贝尔奖牌可以确定第二问答案,奖牌得知是东京大学的小柴昌俊,根据维基百科的页面日本人诺贝尔奖得主根据东京大学及年龄一个个排除找到了梶田隆章,于是找到了宇宙射線研究所 ICRR。
第一问在第二张图片中根据带子上的“statphys28”标志搜索得知会议室日期是 2023 年 8 月 7 日 – 2023 年 8 月 11 日,逐一试过可知答案。
题目 3-4
3、帐篷中活动招募志愿者时用于收集报名信息的在线问卷的编号(以字母 S 开头后接数字)是多少? S123456789
4、学长购买自己的博物馆门票时,花费了多少日元? 0
根据文中提到“饭后,你们决定在附近散步”,那么在确定了拉面店的位置后可以方便确定博物馆和广场喷泉的位置,根据图中二维码确定了一信拉面店的位置,在地图周围再找喷泉可以找到上野恩赐公园 ,那么原文中提到“ 马路对面”可以确定博物馆为东京國立博物館(周围有一堆博物馆)。
第二关容易确定的是在线问卷,因为一旦找到就可以完全确定,设置搜索时间8月7日-8月11日搜索“上野恩赐公园”可得知梅酒活动。打开网页翻译可以找到志愿者招募。
然后是博物馆票价,根据搜索结果一个个试,结果全部失败,直接脚本暴力遍历了以10递增10到10000的价格,结果一个都不可以,😖。反复检查志愿者招募的结果是否正确,确定志愿者一题绝对试对的,那么就是票价的问题,填了个0,结果第二关过了。。。。。。。
坑爹呀,是学长,免费!!!!!!
事后翻看东京国立博物馆的网页发现了一条校园会员
为了通过博物馆促进学生们对文物和日本文化的理解,我们设立了“东京国立博物馆校园会员”制度。成为会员的大学和专科学校的学生、教师们可以免费无限次参观综合文化展(常设展),另外还可享受特展门票和各种活动等的折扣服务。
题目 5-6
5、学长当天晚上需要在哪栋标志性建筑物的附近集合呢?(请用简体中文回答,四个汉字)
活动中心 安田讲堂
6、进站时,你在 JR 上野站中央检票口外看到「ボタン&カフリンクス」活动正在销售动物周边商品,该活动张贴的粉色背景海报上是什么动物(记作 A,两个汉字)? 在出站处附近建筑的屋顶广告牌上,每小时都会顽皮出现的那只 3D 动物是什么品种?(记作 B,三个汉字)?(格式:A-B) 熊猫-秋田犬
搜索关键词上野站 "ボタン&カフリンクス"看见只有一个搜索结果(现在你再去看应该就不止一个结果了😏),点进去看见一个粉色熊猫,那没错了。

根据最后一张图搜索可以作者去了 PARCO澀谷,然后搜索“澀谷 3D 广告”,可得知是秋田犬。
只差最后一问了,只能找到邮轮夜游的旅游信息,不知道什么集合地点。学长为什么要单独行动呢?那只能是和学术会议有关了,为什么这么确定因为在查看statphys28 官网信息中的看到了参观彩虹大桥的邮轮是一样的 确定了就可以找到安田讲堂了。
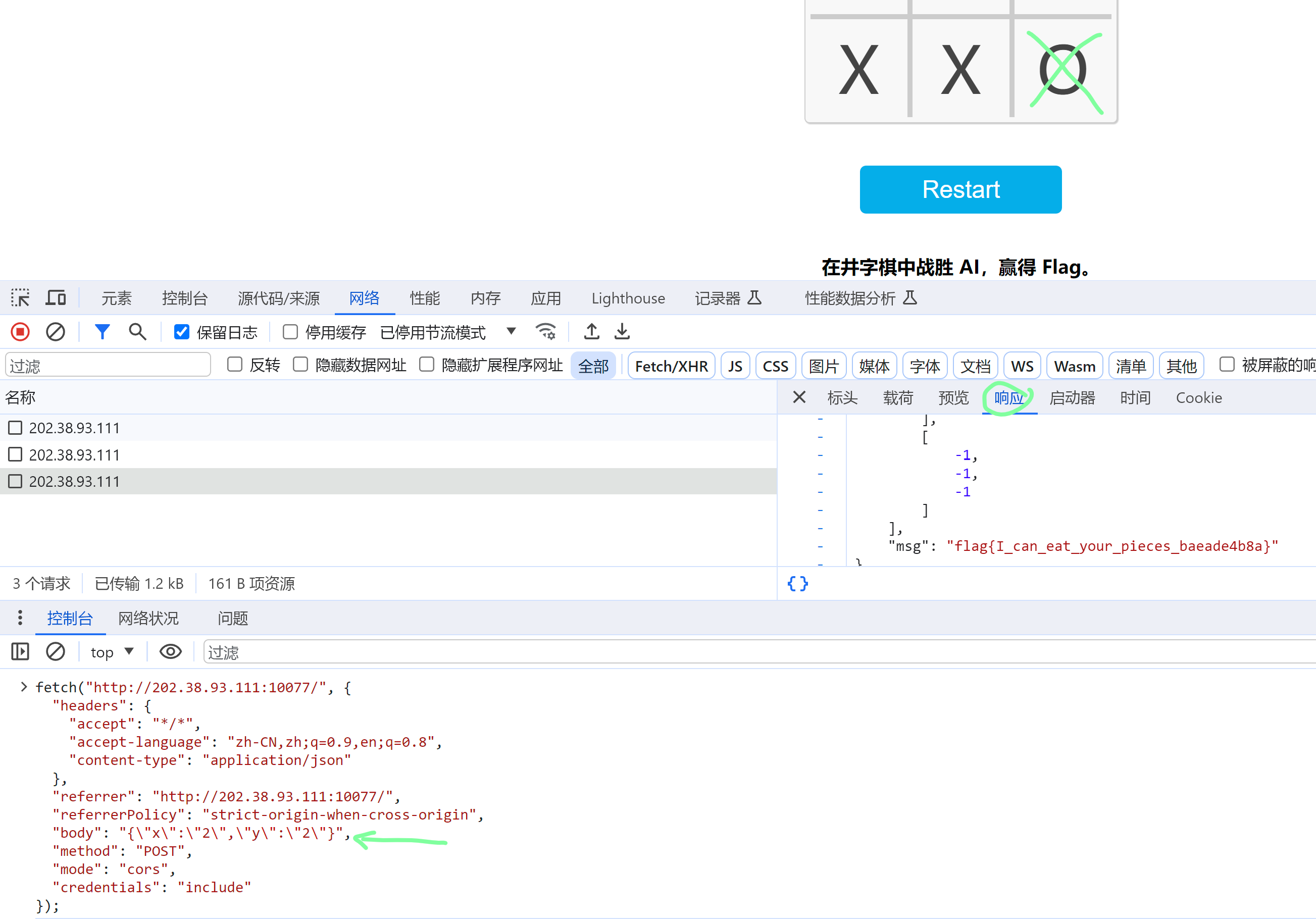
赛博井字棋
哈哈,这题不难但是有点意思,想赢的话想办法直接吃掉对手的棋子就可以了!!!
奶奶的睡前 flag 故事
开始也是毫无头绪,陷阱了图片隐写的套路中,直到我观察到题目中加粗的关键词后,通过搜索知道了“Acropalypse”漏洞(CVE-2023-21036),根据相关报道利用在线工具acropalypse即可解题。
组委会模拟器
这题一看就是要用脚本操作,不难,但是你要用脚本模拟发送网络请求的话,你会一口气接收到所有的信息,但是你撤回信息的请求是有时间要求的,你过早撤回信息会失败,也就是说你还要处理时间相关的问题。
所以推荐在前端页面来处理。
虫
和上面的题目一样,关注题目中加粗的字,搜索可知要用SSTV来解码音频,就在手机上安装了robot36 SSTV Image Decoder图像解码软件。
我把手机拿在手上去接收音箱发出来的声音信号得出的图片基本不可辨识,但是我把手机放到音箱上就可以识别出图片信息了。
JSON ⊂ YAML?
这题,简直了就是大海捞针了,协议规范我是不会读的,相关搜索结果一个个看呗,一个个试呗,还好都是试出来了,也耗了比较长的时间。
实验的脚本我直接在Google colab上跑的以免影响本地的环境。
json not same YAML1.1 : 1e2
json not YAML1.2: {"a": 0,"a": 1}
Git? Git!
> git reflog
ea49f0c (HEAD -> main) HEAD@{0}: commit: Trim trailing spaces
15fd0a1 (origin/main, origin/HEAD) HEAD@{1}: reset: moving to HEAD~
505e1a3 HEAD@{2}: commit: Trim trailing spaces
15fd0a1 (origin/main, origin/HEAD) HEAD@{3}: clone: from https://github.com/dair-ai/ML-Course-Notes.git
> git reset --hard 505e1a3
HTTP 集邮册
这题我收集到了 12 个状态码:[100, 200, 206, 304, 400, 404, 405, 412, 413, 414, 416, 505],都是按照 MDN 手册中 HTTP header 和 HTTP响应状态码一个条目一个条目看过来试过来的。中途还一度怀疑是不是还要去看nginx源码,还好不用,如果你看了源码你会发现第十三个状态码。
先看让 nginx 返回首行无状态码的响应GET /\r\n\r\n,参照这里What, at the bare minimum, is required for an HTTP request?
HTTP/1.1 100 Continue
Expect: 100-continue\r\n
HTTP/1.1 200 OK
GET / HTTP/1.1\r\n
HTTP/1.1 206 Partial Content
Range: bytes=20-100, 20-65, 190-\r\n
HTTP/1.1 304 Not Modified
If-None-Match: "64dbafc8-267"\r\n
或者
If-Modified-Since: Tue, 15 Aug 2023 17:03:04 GMT\r\n
HTTP/1.1 400 Bad Request
xxx 随便什么都可以
HTTP/1.1 404 Not Found
GET /33 HTTP/1.1\r\n
HTTP/1.1 405 Not Allowed
POST / HTTP/1.1\r\n
HTTP/1.1 412 Precondition Failed
If-Match: xxx\r\n
HTTP/1.1 413 Request Entity Too Large
Content-Length: 6438267\r\n
HTTP/1.1 414 Request-URI Too Large
过长url
HTTP/1.1 416 Requested Range Not Satisfiable
Range: bytes=1920-\r\n
HTTP/1.1 505 HTTP Version Not Supported
GET / HTTP/2\r\n
HTTP/1.1 501 Not Implemented
Transfer-Encoding: gzip\r\n
Docker for Everyone
搜索可得知Docker 用户组提权的方法,要看到根目录的下面的flag只需要执行docker run -v /:/hostOS -it alpine,因为flag文件是个软连接文件,直接访问/hostOS/flag是不行的,cat /hostOS/dev/shm/flag可知flag。
惜字如金 2.0
先把惜字如金的规则给搞懂了
vowel = "AEIOUaeiou"
def p1(w):
'''第一原则(又称 creat 原则):
如单词最后一个字母为「e」或「E」,
且该字母的上一个字母为辅音字母,
则该字母予以删除。
'''
if w[-1] in vowel:
if w[-2] not in vowel:
w = w[:-1]
return w
def p2(w):
'''第二原则(又称 referer referrer原则):
如单词中存在一串全部由完全相同(忽略大小写)的辅音字母组成的子串,
则该子串仅保留第一个字母。
'''
pre = None
z = ''
for i,c in enumerate(w):
if c not in vowel:
if c.upper() == pre:
continue
pre = c.upper()
z += c
return w
def ZXRJ(w):
w = p1(w)
w = p2(w)
return w
字母就藏在 cod[e]_dict 中,我要想办法补全,因为给的源码文本通过上面的规则把一些字母去掉了。但是固定的字符”flag”、”{“和”}”可以帮忙确定一些被去掉字母的位置。
cod_dict = []
cod_dict += ['nymeh1niwemflcir}echaet*'] # 0-24
cod_dict += ['a3g7}kidgojernoetlsup?h*'] # 25-48
cod_dict += ['uulw!f5soadrhwnrsnstnoeq'] # 49-72
cod_dict += ['*ct{l-findiehaai{oveatas'] # 73-96
cod_dict += ['*ty9kxborszstguyd?!blm-p'] # 97-120
cod = ''.join(cod_dict)
input_codes = [53, 41, 85, 109, 75, 1, 33, 48, 77, 90,
17, 118, 36, 25, 13, 89, 90, 3, 63, 25,
31, 77, 27, 60, 3, 118, 24, 62, 54, 61,
25, 63, 77, 36, 5, 32, 60, 67, 113, 28]
output_chars = [cod[c] for c in input_codes]
print(''.join(output_chars))
🪐 高频率星球
刚好用过这个工具asciinema
asciinema cat restore.rev > output.js
手工清除多余的部分恢复成js文件,执行即可.
🪐 小型大语言模型星球
很遗憾,只做出来了第一个。
和我们日常使用的大语言模型不同,题目中用的小模型并不能理解你说的内容,你要他重复你的输入他也只是接着补全而已,补的内容似乎跟你给出的内容也没有什么上下文的关系。
> Don't say you are not smart just because you struggled on one test,
but you did it. You are smart and brave and you can do anything you set your mind to."
Lily felt better and thanked her
👏👏👏 flag1: flag{} 👏👏👏
第一个瞎尝试,尝试出来了,第二个怎么都不行,题目限制消息长度在7,看来是要我们暴力破解了,把模型下载下来本地跑呗。
但我没有暴力,而是尝试枚举,从网上下了一堆的单词列表,结果最接近的是
> relatively
accepted the invitation and started to play with the other kids. He had so much fun that he forgot all about the invitation.\n\nThe moral of\n
🎉🎉🎉 flag2: `flag2!!!!!` 🎉🎉🎉
还是长了,我试了四六级、专业英语、TOEFL的都没有找到,放弃做别的题目了。
🪐 流式星球
根据所给的 create_video.py 文件可以看出如何将视频文件转化成video.bin文件的方法,利用 opencv 读取视频每一帧的画面像素信息,但是将这个多维数组扁平化为一维的列表一股脑的写入了bin文件中,也就是说丢失了视频的宽、高、总帧数信息,你要去尽量还原这个视频,至少能够看清其中隐藏的内容。
我先是一步步摸索其中的过程将转化为bin文件和从bin还原成mp4的过程用python实现了
import cv2
import numpy as np
def to_bin(file, output):
vidcap = cv2.VideoCapture(file)
frame_count = int(vidcap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_width = int(vidcap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(vidcap.get(cv2.CAP_PROP_FRAME_HEIGHT))
buffer = np.empty(shape=(frame_count, frame_height, frame_width, 3), dtype=np.uint8)
for i in range(frame_count):
success, frame = vidcap.read()
if not success:
raise Exception(f"Failed to read frame {i}")
buffer[i] = frame
buffer1 = buffer.reshape((frame_count * frame_height * frame_width, 3))
buffer2 = buffer1.ravel()
buffer2.tofile(output)
return frame_count, frame_height, frame_width
def to_mp4(binfile, chw, outputmp4, fps=24,add=False):
frame_count, frame_height, frame_width = chw
read_buffer2 = np.fromfile(binfile, dtype=np.uint8)
if add:
print(len(read_buffer2))
add = frame_count*frame_height*frame_width*3 - len(read_buffer2)
read_buffer2 = np.append(read_buffer2, np.zeros((add),dtype=np.uint8))
print(len(read_buffer2))
read_buffer1 = read_buffer2.reshape((frame_count * frame_height * frame_width, 3))
read_buffer = read_buffer1.reshape((frame_count, frame_height, frame_width, 3))
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(outputmp4, fourcc, fps, (frame_width, frame_height))
for frame in read_buffer:
out.write(frame)
out.release()
cv2.destroyAllWindows()
print("ok!?")
理解后你会知道bin文件的字节数应该是frame_count, frame_height, frame_width, 3的乘积,恰好给定的bin文件字节数 135146688 通过分解质因数12可知135146688 = 3 x 2^3 x 409 x 1721,看起来对应一个视频的宽高和帧很对应是吧,可是我通过各种排列组合尝试来还原的均失败,没有可识别的图像。另外考虑到原脚本中随机去掉了100内的直接,那么我再在135146688,135146789范围内一个个分解质因数,只要是质因数里包含3,就可以拿出来再尝试一顿排列组合操作。
# 网上随便找的一段
from math import sqrt
def breakdown(N):
result = []
for i in range(2, int(sqrt(N)) + 1):
if N % i == 0: # 如果 i 能够整除 N,说明 i 为 N 的一个质因子。
while N % i == 0:
N //= i
result.append(i)
if N != 1: # 说明再经过操作之后 N 留下了一个素数
result.append(N)
return result
for i in range(135146688, 135146789):
res = breakdown(i)
if 3 in res:
print(res, i)
[2, 3, 409, 1721] 135146688
[3, 5005433] 135146691
[2, 3, 22524449] 135146694
[3, 7, 223, 28859] 135146697
[2, 3, 5, 13, 11551] 135146700
[3, 45048901] 135146703
[2, 3, 193, 116707] 135146706
[3, 15016301] 135146709
[2, 3, 23, 103, 2377] 135146712
[3, 5, 11, 19, 3919] 135146715
[2, 3, 7, 37, 3221] 135146718
[3, 43, 1047649] 135146721
[2, 3, 11262227] 135146724
[3, 181, 82963] 135146727
[2, 3, 5, 4504891] 135146730
[3, 45048911] 135146733
[2, 3, 17, 55207] 135146736
[3, 7, 13, 495043] 135146739
[2, 3, 41, 83, 6619] 135146742
[3, 5, 1001087] 135146745
[2, 3, 11, 1023839] 135146748
[3, 761, 59197] 135146751
[2, 3, 167, 44959] 135146754
[3, 29, 59, 113, 233] 135146757
[2, 3, 5, 7, 349, 461] 135146760
[3, 31, 484397] 135146763
[2, 3, 211, 106751] 135146766
[3, 389, 115807] 135146769
[2, 3, 19, 67, 983] 135146772
[3, 5, 241, 7477] 135146775
[2, 3, 13, 107, 16193] 135146778
[3, 7, 11, 23, 61, 139] 135146781
[2, 3, 347, 4057] 135146784
[3, 17, 101, 26237] 135146787
眼花,哪怕去掉那种特别离谱的数值,我试了遍都没有发现有意义的图像(其实倒数第三个可以)。
后来才发现暴力破解才是正解,逐步迭代。我在宽度:212 高度:506可以到可以识别的图像,

并在赛前半个小时提交了flag,真的惊险。。。。。
赛后总结,这种情况下先调整图像的宽度,再调整高度。
视频分辨率为 427 x 759。也就是135146781 = 3^2 x 7 x 11 x 23 x 61 x 139 = 3 x 427 x 759 x 139
🪐 低带宽星球
第一问送分题,找一个在线压缩png图片的工具即可完成。第二问我看到到最后也只有4个人答出来了😓
异星歧途
好吧,现在ctf比赛里都开始流行玩游戏了是吧!像素工厂我还真的没有玩过,甚至没听说过,只听说过异星工厂,玩过戴森球计划,好!我已经花十分钟完全了解了这个游戏。误,走错片场了。。。。。
32个开关,每8个一组,4组都能输出电源代表成功,按照此时开关状态的顺序可通关。我是从右边开始的,因为右边的开关会有响应有状态变化,左边的只有在全部正确的状态下才会有响应和变化,没办法试,所有我就瞎试把右边的两个试过了,左边的则不行,后来才弄懂有逻辑开关,点进去可以看到相应的代码,左一太简单了,一眼过,左二复杂一点我先给翻译成了python代码。
for z in range(0, 256):
s1,s2,s3,s4,s5,s6,s7,s8 = [int(s) for s in f"{z:08b}"]
print(s1,s2,s3,s4,s5,s6,s7,s8, ":", z)
# game
t = s1 << 7
num = t
t = s2 << 6
num += t
t = s3 << 5
num += t
t = s4 << 4
num += t
t = s5 << 3
num += t
t = s6 << 2
num += t
t = s7 << 1
num += t
t = s8
num += t
print(f'num:{num} t:{t}')
en = 0
i = 0
while i <16:
fl0 = i ** 2
if int(fl0) != int(num):
i += 1
else:
en = 1
break
fl1 = int(0 == s1)
fl2 = int(0 == s6)
fl3 = fl1 | fl2
if fl3 == 0:
print(f'en={en}!!!')
else:
en = 0
print(f'en={en}')
print(f"i:{i} en:{en} fl0:{fl0} fl1:{fl1} fl2:{fl2} fl3:{fl3}")
这里稍有不注意,就容易把运算符 ^ 和 ** 搞混了,因为其中一直都在做位运算,所以就直接照抄了^运算符,其实这里平方运算。否则不会有唯一解,还好这个游戏还提供观察变量的位置,要不还不容易发现蹊跷的位置
