上个星期参加了这场比赛,就像去年一样。
根据签到题的完成情况可知,有1012人参加了比赛。相比较上届比赛签到题只有六百多人的完成情况来看,这届的参赛人数比上届提高了许多,然后上届的签到题稍微难了一点至少不是直观的,这届的签到题真是有手就行。

明天中国科学技术大学第十届信息安全大赛也要开始了,我也要参加,就像去年我也参加了2022 hackergame一样,CTF比赛还是很有意思的。
这届的比赛已经结束,官方已经公布了比赛的Writeup,我也来记录一下我的解题过程。
一眼盯帧(签到题)
很简单用ffmpeg把gif图片的每一帧图片截取出来即可观察到flag,不过得到最终flag还需要将字符串通过ROT13转换一下即得到最终flag。
ffmpeg -i prob23-signin.gif frame_%d.png
小北问答!!!!!
很可惜,总共六道题只答出来5道题,还有一道没有答出来。只拿到了半份flag。
-
在北京大学(校级)高性能计算平台中,什么命令可以提交一个非交互式任务?
sbatch搜索可知:北京大学高性能计算平台使用教程
-
根据 GPL 许可证的要求,基于 Linux 二次开发的操作系统内核必须开源。例如小米公司开源了 Redmi K60 Ultra 手机的内核。其内核版本号是?
5.15.78在B站上搜索发现有人发手机相关视频,但是数字模糊不太看得清。于是在谷歌图片搜索
Redmi K60 Ultra 全部参数,翻看找到了清晰的图像。 -
每款苹果产品都有一个内部的识别名称(Identifier),例如初代 iPhone 是 iPhone1,1。那么 Apple Watch Series 8(蜂窝版本,41mm 尺寸)是什么?
Watch6,16 -
本届 PKU GeekGame 的比赛平台会禁止选手昵称中包含某些特殊字符。截止到 2023 年 10 月 1 日,共禁止了多少个字符?(提示:本题答案与 Python 版本有关,以平台实际运行情况为准)
-
在 2011 年 1 月,Bilibili 游戏区下共有哪些子分区?(按网站显示顺序,以半角逗号分隔)
游戏视频,游戏攻略·解说,Mugen,flash游戏直接在web archive中搜索现在的哔哩哔哩域名
bilibili.com是找不到的,不过可以通过搜索bilibili.tv找到相关页面,不过不是2011年1月的。 -
这个照片中出现了一个大型建筑物,它的官方网站的域名是什么?(照片中部分信息已被有意遮挡,请注意检查答案格式)
philharmonie.lu谷歌图片搜索
tuspark "z-park",得知是参加IASP 2023 Luxembourg卢森堡的活动 。在此页面2023年IASP世界大会的社交活动环节令人期待可以看到相应的建筑符合照片,得到结果。
{kind=link}
Z 公司的服务器
只拿到一半flag,并没有找到是用什么协议来传输的。在流量包里发现了flag.jpg图像但是无法解码。
服务器
通过观察抓包文件,手撸了一个脚本出来,可以得到flag1,碍于对于协议的不了解,无法正确解码抓包文件中的flag.jpg图像。
from pwn import *
def print_hex(s):
h = ' '.join(s[i:i+2] for i in range(0, len(s), 2))
print('{}: {}\n'.format(len(s)//2,h))
return h
r = remote('prob05.geekgame.pku.edu.cn',10005)
print(r.recv(4096))
token = b'{your token}'
print('> ', token)
r.sendline(token)
d = r.recv(4096)
print_hex(d.hex())
payload = bytes.fromhex('2a2a184230313030303030303633663639340a0a')
print('> ',payload)
r.send(payload)
d = r.recv(4096)
print_hex(d.hex())
# 2a2a184230393030303030303030613837630a0a
payload = bytes.fromhex('2a2a184230393030303030303030613837630a0a')
print('> ',payload)
r.send(payload)
d = r.recv(4096)
print_hex(d.hex())
print(d) # flag
流量包
我看官方writeup的解法还是在理解协议的解出上将数据包解码出来的。选手交流后我感觉预期解应该是:知道是用什么协议后,利用现有的协议客户端和流量包里的数据,模拟一个服务端和客户端通讯从而拿到数据,毕竟理解一个协议要耗费大量时间,何不利用现有工具呢,而且这是个古老且并不是被广泛流行的协议。
赛后复盘
知道数据是用ZMODEM协议传输进行传输的,完全可以利用现有支持此协议的终端模拟器来完成第一问,在Windows系统下,Windows Terminal是不支持的,但是 MobaXterm 是支持的,但是不是自动弹出文件选择框,需要你手动选择一下。
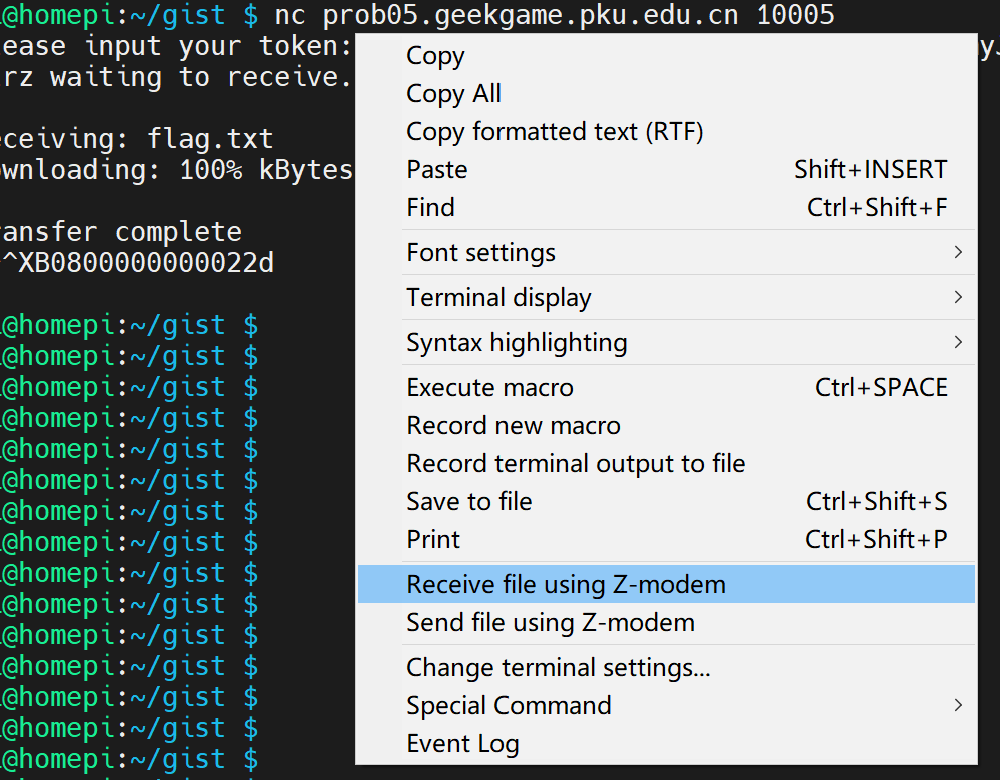
利用现有工具即可完成第一问,显然这是预期解。
也就是说你并不需要安装什么 lrzsz 工具,只要终端支持此协议就行,但我还是建议你安装一个 lrzsz 来了解一下这个工具是怎么工作的,在直觉上与我们现在常用的文件传输工具还是有区别的。上传下载文件都是在远程主机的shell里执行。
SZ send file 需要文件名参数,mobaxterm 中选择 receive file using z-modem 下载文件。
RZ receive file 不需要文件名参数,mobaxterm 中选择 send file using z-modem 上传文件。
第二问我们用流量重放来解决。首先从流量文件中导出数据,我们在 wireshark 中追踪TCP流可以看到传输的数据。如下图
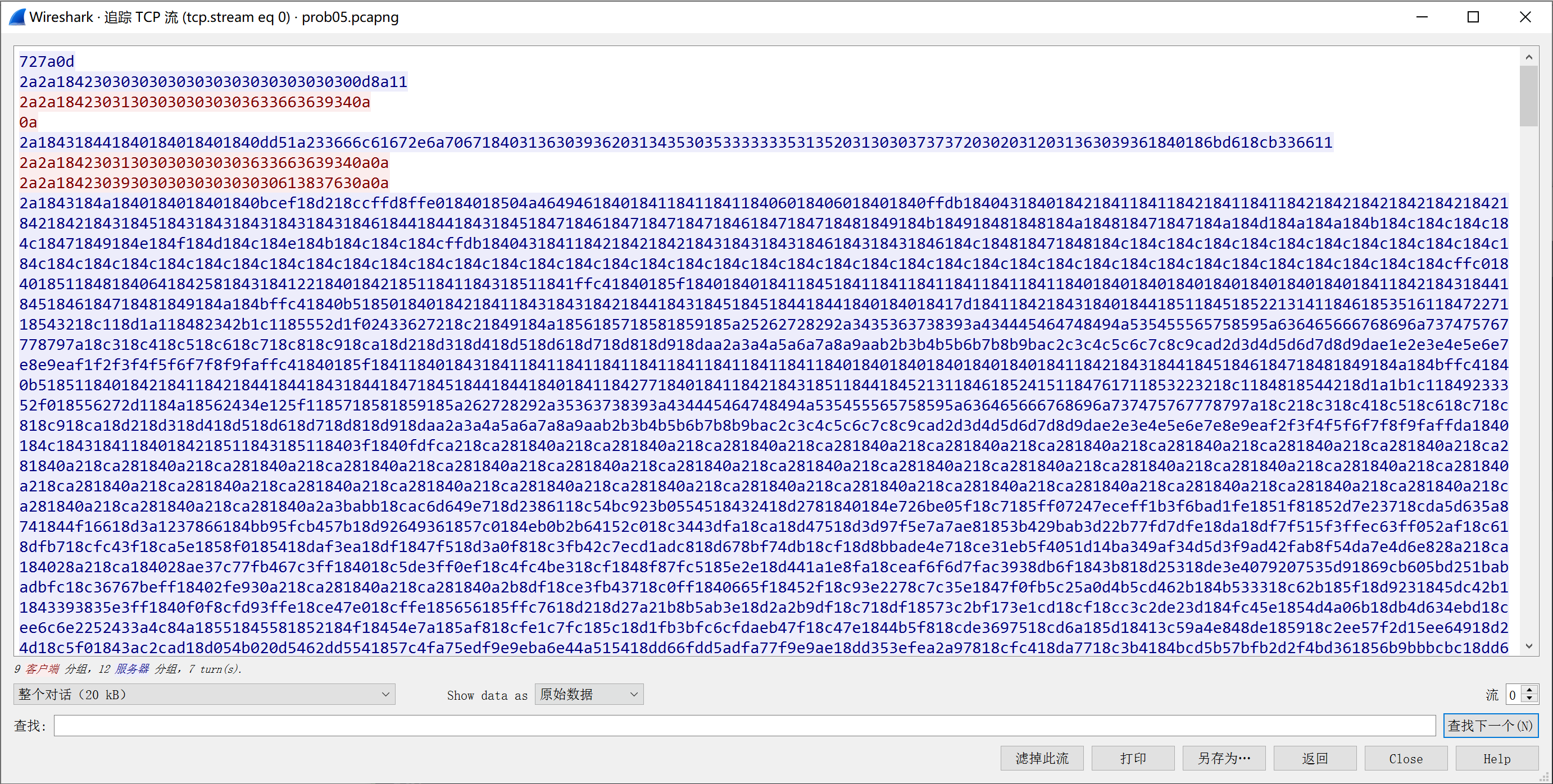
将其中的传送文件端的数据拷贝出来,用下面的脚本准备进行流量重放,流量文件中将接收文件端的数据换成空行,以便完成整个通信。
from pwn import *
context.log_level = 'debug'
p = listen(7777)
with open('stream', 'r') as f:
a = f.read()
b = a.splitlines()
for i in b:
if i == "":
print(p.read(1024))
else:
p.send(unhex(i))
p.shutdown()
p.close()
我们监听7777端口,等待连接来传输文件,这里我们需要利用该工具的 –tcp 功能。
发送端:sz --tcp-client [host]:[port] filename
|
v
接收端:rz --tcp-server
发送端:sz --tcp-server filename
|
v
接收端:rz --tcp-client [host]:[port]
上面的脚本相当于执行了sz --tcp-server flag.jpg,所以我们要执行rz --tcp-client [host]:7777来接收文件,这样在当前目录下你就可以看见 flag.jpg 文件了。当然你用上面的nc [host] 7777如法炮制也可以。
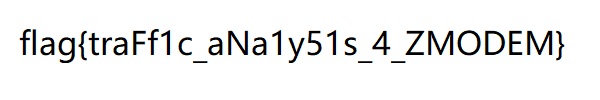
基本功
利用现有的bkcrack工具进行明文攻击即可。刚好我以前了解过破解加密的zip压缩文件
简单的 Flag
zip文件固定的四个字节加上猜测压缩包里的文件名称也是chromedriver_linux64。

> .\bkcrack.exe -C ".\challenge_1.zip" -c "chromedriver_linux64.zip" -p ziphead -x 30 6368726F6D65647269766572
0062ff52 09f8b778 0741b1cc
> .\bkcrack.exe -C "challenge_1.zip" -c "flag1.txt" -k 0062ff52 09f8b778 0741b1cc -d "flag1.txt"
冷酷的 Flag
观察pcapng文件得知固定的文件头

> .\bkcrack.exe -C ".\challenge_2.zip" -c "flag2.pcapng" -p .\pcapnghead
e256a41d 11a08879 7e41f9c2
> .\bkcrack.exe -C "challenge_2.zip" -c "flag2.pcapng" -k e256a41d 11a08879 7e41f9c2 -d "flag2.pcapng"
wireshark观察流量包的内容可得flag。
麦恩·库拉夫特
这是一道和minecraft游戏有关的题目,我在这个题目上消耗(浪费)了好长的时间。
flag1: 探索的时光
好久没玩 Minecraft了,打开我的老电脑先进游戏探索看看,熟悉熟悉操作,跟着火把走,先是看到了一个牌子显示“wrong way”,原路返回换了一条路走,走到一大片岩浆地带看到了第一个flag flag{Exp0rIng_M1necRaft_i5_Fun}。
flag2: 结束了?
游戏肯定有没有这么简单,先从各种游戏命令开始学起,改变游戏各种模式,在地图里传来传去没有发现什么有意义的线索反而被偶然中发现的藏宝图给带歪了路线,在找资料的过程中常看到有人提到一个叫做 NBTExplorer 的工具,果然有用,在存档文件中通过搜索字符串flag找到了第二个flag flag{pAR3inG_ANvI1_iSeAaasY2},在一个封闭的钻石块堆砌的空间里。
同时找到了第三个flag相关的位置。
flag3: 为什么会变成这样呢?
来到第三个flag的位置,红石电路组成的显示屏在播放以十六进制数字显示的二进制数据,对游戏机制的不熟悉让我打起来通过录像识别红石电路的主意。目视显示屏的话,因为刷新率太低,两个字符显示之间的状态非常影响肉眼的识别,我只能在别的位置看能不能识别十六进制的数据,如下图的位置可以比较准确的识别到数据,我肉眼识别的前十几个数据,发现是PNG的文件头,看来还是有路可以走的,于是….
1、先是对游戏画面进行录像,录像视角如下图所示,主要是识别哪条红石电路上红色亮起表示的信号。

2、对视频文件进行处理成一张张的图片便于程序识别。
ffmpeg ffmpeg -i p.mp4 -ss 00:00:45 -to 00:12:15 -vf fps=1/0.2 p/%d.bmp
截取了我录制的视频从45秒到12分钟15秒的片段,以每秒5张总共3450张图片,因为提示是每秒2.5字节的速度,也就是说2秒5个字节,因为一个字节需要两个字符的十六进制数字来表示,也就是说2秒要传10个字符信号,所以是每秒5张图片。
3、用python的PIL来识别。很幸运居然成功了,虽然我是在时间截止后才成功让脚本跑出图片,但是确实证明录屏识别红石信号是可行的。写程序包括运行的阶段也经历的很多调试的过程,主要在像素点的选取上。
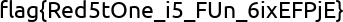
from PIL import Image
from pathlib import Path
import binascii
threshold = 60
folder = "Videos/Captures/p/"
def calc(image, points):
"""
return red glowing
"""
result = 0
for p in points:
x,y = p
r,g,b = image.getpixel((x,y))
print(f"{x},{y}({r},{g},{b})",end=" ")
if r > threshold:
result += 1
return result
# 要检查的点的坐标(x, y), 每个字符取了多个位置
checkp = [
[(268, 690),(273,711)], # 0
[(367, 690),(373,711)], # 1
[(467, 690),(471,712)], # 2
[(567, 690),(568,709)], # 3
[(666, 690),(672,724)], # 4
[(767, 696),(767,745)], # 5
[(865, 677),(866,714)], # 6
[(967, 680),(960,737)], # 7
[(1065, 698),(1065,715)], # 8
[(1165, 698),(1164,721)], # 9
[(1264, 695),(1262,722)], # a
[(1364, 695),(1361,722)], # b
[(1464, 695),(1457,717)], # c
[(1564, 695),(1555,736)], # d
[(1663, 695),(1655,716)], # e
[(1762, 698),(1756,724)], # f
]
hexb = [] # 二进制字节的十六进制数字字符
for n in range(9,3451): # 图片数量
filename = Path(folder, '{}.bmp'.format(n))
image = Image.open(filename)
print(f"open {filename.name}")
light = '' # light chars
for i, points in enumerate(checkp):
h = hex(i)[-1]
result = calc(image, points)
if result > 0:
light += h
print(f"{h} <{result}>")
else:
print(f"{h}")
# every frame only get one light
# one of two light must be previous one
if len(light) == 0:
print('[empty]')
elif len(light) == 1:
pass
elif len(light) > 1:
try:
preb = hexb[-1]
except IndexError:
preb = ''
print("light:{} preb:{}".format(light, preb))
# 这一行依旧亮光,可能是上一个信号还未完全关闭,
# 如果和上一个信号相同则去掉
light = ''.join(set(light) - set(preb))
# after clean lights left behind
if len(light) == 1:
hexb.append(light)
print(f'choose: {light}')
else:
# 有一些异常发光的像素点需要去手动检查来调整坐标
print('[break] pixel need check!!!', light)
break
print('\n')
# write result
png = ''.join(hexb)
print("PNG:{}: {}".format(len(png),png))
# 直接二进制写入图片得到
byte_array = binascii.a2b_hex(png)
with open('flag.png', 'wb') as f:
f.write(byte_array)
Emoji Wordle
凑巧,前不久了解了一下什么是JWT,很明显就知道这题这么做了。
Level 1
发现请求不需要任何身份验证也不需要提交token,提示是固定组合,那么用脚本暴力提交就可以了,先是批量请求获取了答案是在128个emoji,然后选取64个提交再根据结果的提示调整,每一次都是一个新的请求这样不会受服务端返回cookie的影响,多试几次就得到了,其实是和第三关的脚本差不多,下面再放脚本。
Level 2
观察请求,从服务器的响应中得知采用了JWT,在 cookie 中解码可得知 target emoji 是什么,直接提交即可。
Level 3
其实和第一关一样,第一关的请求除了带上你的 guess 的 emoji 你不需要其他的信息也不用理会服务器返回来的 cookie 这样就不会只有63次的限制。同样第三关要破除三次提交的限制,只需带上第一次服务器返回的 PLAY_SESSION 信息,这个 PLAY_SESSION 至少在一分钟的时间限制下是有效的,疯狂提交吧。
import requests
import base64
import random
import re
X = '👚💈🐞👽💍🐜💉🐕💊👊🐒👠💂👾👰👔🐸🐘🐬👣👐🐺🐩💏👿👓🐲👇👉🐷👳💄🐧🐛💅👋💀🐥👱🐡👵🐽🐗🐓🐰👷👒👦🐚💎🐱🐝👅🐿👲🐦👫👜🐖👑🐶💃🐪🐻🐵🐾👏👁🐨👈🐤👘💌👝👧👼👞👭👛👺👖👎👃👻👍👸👀🐐💆💋👤🐭🐫👆🐮👩👗🐳👬🐼👹🐔🐹👯🐠👶🐴👌🐟🐯💁👴👡💇👟👪👨👕👥👄👢🐑👙🐙🐣👮🐢👂'
wordle = {
'🟩': ['◽']*64,
'🟨': set(),
'🟥': set(),
'session': 'x.aW5pdA==.x'
}
URL = "https://prob14.geekgame.pku.edu.cn/level3"
INTI_EMOJI = X[0:64]
def session_data(payload):
return base64.b64decode(payload+'==').decode()
def print_wordle(w):
print('🟨:{}{}'.format(''.join(w['🟨']), len(w['🟨'])))
print('🟥:{}{}'.format(''.join(w['🟥']), len(w['🟥'])))
print('🟩:{}{}'.format(''.join(w['🟩']), 64-w['🟩'].count('◽')))
# print('JWT: ', session_data(w['session'].split('.')[1]))
def gen_wordle(placehold: list) -> list:
x = set(X) - wordle['🟥']
# x = x | wordle['🟨']
# print("choice 1/{} {}".format(len(x),''.join(x)))
for i, e in enumerate(wordle['🟩']):
if e == '◽':
if len(wordle['🟨']) == 0:
placehold[i] = random.choice(list(x))
else:
placehold[i] = random.choice(list(x | wordle['🟨']))
else:
placehold[i] = e
return placehold
def find_result(content) -> str or None:
pattern = r'results.push\("(.*?)"'
match = re.search(pattern, content)
if match:
return match.group(1)
else:
return None
def find_times(content):
pattern = r'Number of guesses remaining: (\d+)'
match = re.search(pattern, content)
if match:
return match.group(0)
else:
return None
def find_flag(content):
pattern = r'flag{.+}'
match = re.search(pattern, content)
if match:
return match.group(0)
else:
return None
# guess Emoji
for i in range(1000):
print("try {}:".format(i+1))
print_wordle(wordle)
emoji = gen_wordle(list(INTI_EMOJI))
print('🧠:{}'.format(''.join(emoji)))
params = {'guess': ''.join(emoji)}
cookies = dict(PLAY_SESSION=wordle['session'])
r = requests.get(URL, params=params, cookies=cookies, timeout=10)
if wordle['session'] == 'x.aW5pdA==.x' :
wordle['session'] = r.cookies['PLAY_SESSION'] # update session!
# get result
result = find_result(r.text)
if result == None:
print(r.headers)
print(r.text)
exit()
print('🌐:{}'.format(result))
# get flag
flag = find_flag(r.text)
if flag:
print(flag)
exit()
# Number of guesses remaining
# print(find_times(r.text))
# time.sleep(0.2)
for i in range(64):
n = result[i]
e = emoji[i]
if n == '🟩':
wordle['🟩'][i] = e
elif n == '🟨':
wordle['🟨'].add(e)
elif n == '🟥':
wordle['🟥'].add(e)
else:
pass
print(r.cookies['PLAY_SESSION'])
汉化绿色版免费下载
普通下载
按照游戏要求的流程走了一遍,输入相同的内容,在一个蓝色背景的页面里显示flag1,但是却看不见相应的文字内容,一定是把文字颜色调成和蓝色背景一样了,于是我想着去修改这个蓝色的游戏资源图片不就好了,就直接在data.xp3中修改二进制内容,毕竟在xp3文件中可以清晰的看见相应的png图片,但是发现不可行,一旦修改图片,游戏运行就报错。后来查找相关资料找到了专门解包 xp3 文件的XP3Viewer解包了文件。逐一查看文件,在 done.ks 文件中找到了 flag1。
高速下载
在查看解包文件的过程中,scenario 文件夹下的 ks 文件很清晰的展现了游戏计算的逻辑,看来是要计算hash值呀。存档文件里一定有重要信息,搜索信息得到了KirikiriTools工具,可以将存档文件转化成文本文件,观察存档文件data0.kdt可知要计算的hash值,反复实验比较从文件datasu.ksd文件可知前一次输入的长度以及输入相应的字母选择次数,那么只要把字母的排列组合计算出来,一个个算可推出前一次的输入,但是要记住对排列组合的内容有重复需要去重否则要耗费巨量的时间。
def permutation(S: str) -> list[str]:
# https://leetcode.cn/problems/permutation-ii-lcci/solutions/207054/python-3-bu-yong-setqu-zhong-zui-jian-dan-dai-ma-b/
n=len(S)
if n==0:
return [""]
res=[]
for i in range(n):
if S[i] in S[:i]: #只需判断S[i]是否在S[:i]中出现过即可
continue
for s1 in permutation(S[:i]+S[i+1:]):
res.append(S[i]+s1)
return res
def calc(flag, target='1'):
# print(flag, target)
h = 1337
for f in flag:
if f == 'A':
h = h*13337+11
if f == 'E':
h = h*13337+22
if f == 'I':
h = h*13337+33
if f == 'O':
h = h*13337+44
if f == 'U':
h = h*13337+55
if f == '}':
h = h*13337+66
h = h % 19260817
if h == target:
print('\nget!!!!! ',flag, target)
# else:
# # print(flag, end="")
return h
if __name__ == '__main__':
chars = ['A']*6 + ['E']*3 + ['I'] + ['O']*6
target = 7748521
for p in permutation(chars):
flag = ''.join(p)+'}'
calc(flag, target)
结语
总共有22道题,还有很多题我没有做出来甚至还有几题都没有认真看,算上我做出来的有几题耗费我很多时间,做这种题目还是很有窍门的,很多尝试是无效的浪费时间的,要是能够理解到出题人的思路和考核点就能节约出大量时间。
赛后的复盘也非常重要。