最近做了几个站点的爬虫工具,在登录的环节需要图形验证码,于是就针对此写了个图形验证码识别功能,还好这个站点的图形验证码很简单,没有费太大的功夫就搞定了。
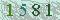
就像这样,没有字母,只有数字,而且字符图像并没有经过旋转或者缩放处理,并且字符图像之间的间隔非常规律,字符图像之间也没有粘连。像这种应该可以做到100%的识别率。
前期准备
图形处理主要使用的是 PIL,不过 PIL 是个很老的库了,许久都不更新了,推荐使用 PIL-fork Pillow 文档
相关的图像操作API The Python Imaging Library Handbook
图片处理
在我们对图形进行识别和匹配前,首先要分离出有效信息(验证码字符信息)和无效信息(背景杂色以及噪点),就是要将彩色的验证码图像转换为灰度图形,然后根据阈值将其二值化,转换成这种黑白图片后,我们才能方便的进行识别处理。
所以我们的第一步就是对图片进行二值化,分离出我需要的字符特征信息,抛弃掉干扰的信息,再来识别字符。
- 先将 RGB 图片转换成灰度图片。降低了色彩空间维度。1
- 选取一个阈值,将图片彻底转换为黑白图片,黑色为有效信息,白色为背景。这个阈值我是手动对比取出的,将各种阈值下生成的黑白验证码图像保存下来,手动观察多个验证码在哪个阈值范围内能够比较好的在尽量保留有效信息的情况下分离出背景信息。各种不同的验证码需要不同对其进行具体分析。2
- 去噪点,有的噪点只是单独的一个像素,有的是一条长的黑条。我们所遇到的情况就是如果单独一个像素的上下左右周围的九个像素点都是空白,则这个像素点为噪点,那么清除掉这个像素点。暴力方法是一个像素点一个像素点的遍历,判断它的四周,我选择了一个稍微取巧的方法,不是单个像素的遍历,而是 2x2 4个像素为一个格子的遍历,如果这个格子中有多个黑色像素或者全是白色像素跳过这个格子,如果只有一个黑色像素,那么对这个像素进行判断,它对周围是不是都是空白,如果是空白则为噪点清除,否则不处理。3
这样我们就得到了完美需要识别的字符信息了。还好这个验证码很简单,没有对字符进行旋转缩放处理,要不然真是是麻烦了,要是还将字符变形粘连到一起,那种情况为人眼都识别不了。
图片切割
接下来就是切割图片字符,分离成一个个的字符,通过存储的模型匹配识别后就可以得出结果了。
我使用的是投影切割法。X轴投影4,就是把二维的图片信息只保留横向的X轴坐标,抛弃掉了竖直的Y轴坐标数据。根据投影后生成列表,根据列表中的数据我们就可以在竖直方向上区分开各个字符了。为了最小化的获取有效字符信息,划分开单个字符图像后再对每个图像进行Y轴投影5,这样图像高度上的空白区域也被切除了出去。
拿着最小范围的字符图片我们就可以进行识别匹配了。
图片识别
首先,选取几个字符图片作为模型存储起来(我遇到的例子很简单只有0-9这几个数字),以此为标准将图片与所有的模型进行比对,取值最大的为结果。我依旧使用上面的投影法来进行对比。
对比采用以下方法,依次对比两张图片X轴垂直方向上有效像素的数量差值,差值总值除以图片的像素获取在X轴上的差异程度。同样再求出在Y轴上的差异程度,最后加权取得一个平均值与1相减最为结果。
下面的图片更直观一点。
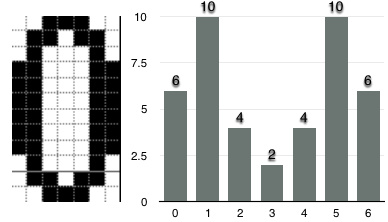
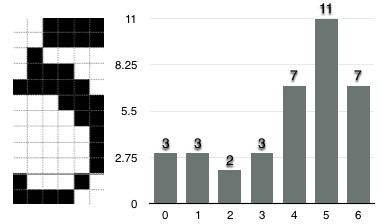
具体可以看此函数7
# X轴上的差值
x = abs(6-3)+abs(10-3)+abs(4-2)+abs(2-3)+abs(4-7)+abs(10-11)+abs(6-7)
# y轴上的差值,同样
y = abs(4-4)+abs(4-4)+abs(2-1)+abs(4-3)+abs(4-5)+abs(4-3)+abs(4-2)+abs(4-1)+abs(4-1)+abs(2-1)+abs(4-2)+abs(3-4)
# 结果
result = 1-(x+y)/2/float(12*6)
我自己测试的结果在此6,只是对比这10个数字来说完全够用了。到这一步就得到结果了,最后实际的使用情况下,验证码的识别正确率基本可以达到100%。我的脚本例子在此https://gist.github.com/xavierskip/95a2a749ceb47ad4eb1ff6d1f8d73c5c
推荐阅读:
Python识别网站验证码
以上都是在WooYun中搜索到的