“准备写一个批量下载虎扑相册的脚本。全当学习python练手。给自己规定时间限制。月底前放出可用版本。” via My 虎扑碎碎念
是的,正在着手写一个批量抓取虎扑相册图片的脚本。
虎扑的相册有许多精彩的体育图片(虎扑是最黄的篮球网站的事我会到处乱说嘛?)
而且是对所有访问者开放的,这一点在抓取的时候麻烦少了许多。
获取网页的文本后抓取其中的图片链接,并转换成最终下载链接(就是原图地址),下载就可以了。
结构很简单。当然下载的部分,调用 wget 就可以了。我的脚本只用处理字符内容就行了。
当然,本着学习的态度来写这个脚本,还是要多动手多练习的。
但是,首先要让它可以跑起来,完成基本功能,然后再添加完善。
处理字符内容就要与 正则表达式打交道。乍一看确实让人头大的,什么乱码这是!!!!
对于正则表达式中的 () 就有了下面的疑问
比如我在一个字符串中匹配 xxxx.jpg or xxxxx.gif or xxxx.png
就用了这样的表达式
[\w]+\.(jpg|gif|png)
输出是
[' jpg ',' gif ',' png ']
()的作用就把我搞糊涂了。直观的来说。正解是使用 (?:)这个无捕获组
[\w]+\.(?:jpg|gif|png)
可以看看这里:http://blog.csdn.net/whycadi/article/details/2011046
最后终于搞清楚了()是什么意思了。
我的理解 首先对整个表达式匹配。而符合 () 中规则的则是匹配输出的内容
s = '<html><div><p>ppp<img>img</img></p><a>a</a></div></html>'
re.findall('<(\w+)>',s)
['html', 'div', 'p', 'img', 'a']
对于抓取某些有特征的字符串,而只需要字符串其中某些内容,()就提供了这样功能,相当于二次抓取吧。
多 () ,或者 () 的嵌套的作用。还需要继续了解。。。
备注:
- 在线 正则 可以方便的对 正则表达式 进行调试
- python 正则表达式基础应用
忘记了基础使用方法就过来看看下图。
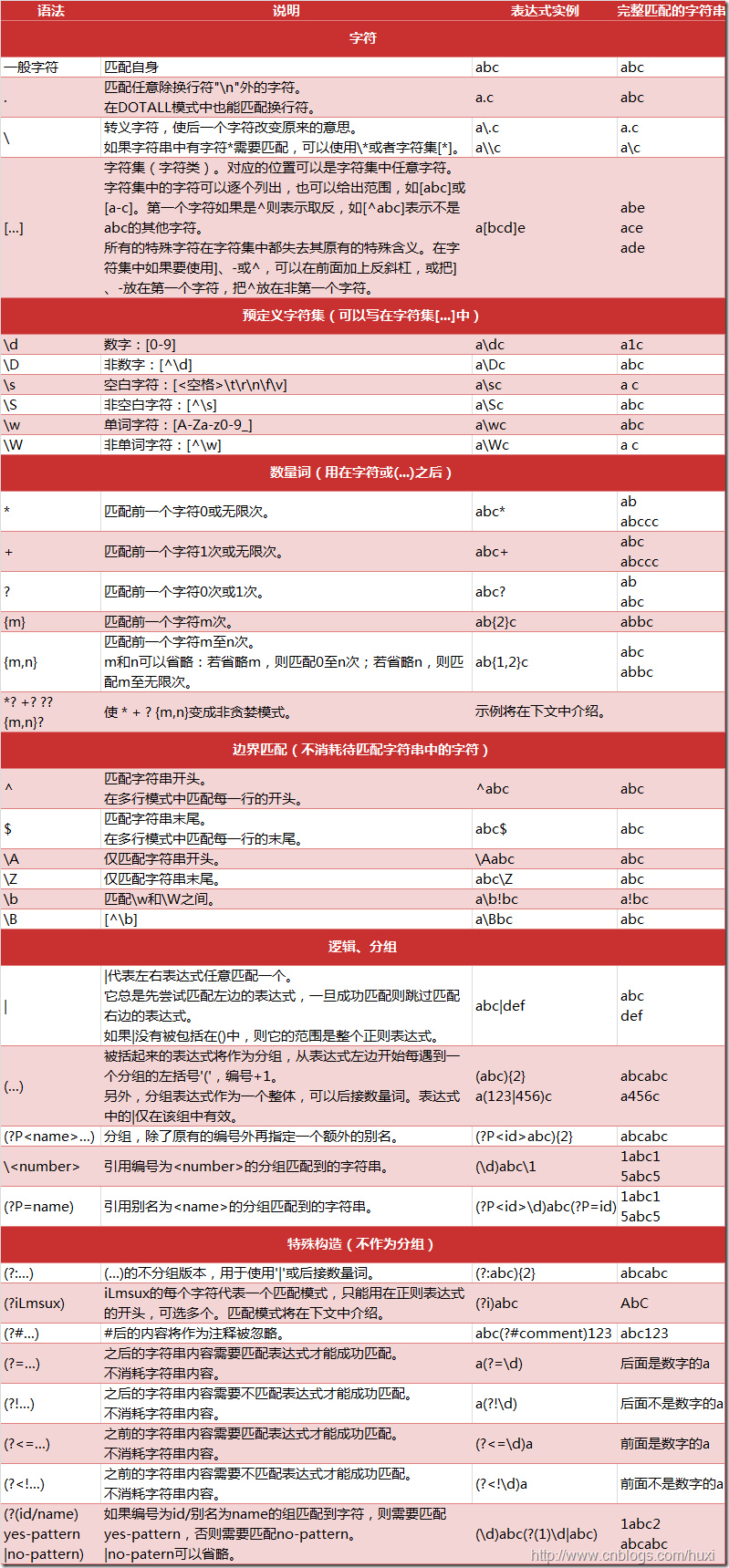
2021/12/26 更新:这个正则表达式工具网站regex101更棒!